
Introduction
Managing database interactions across multiple pipelines can be complex for data engineers. Without proper tracking, SQL queries can become redundant, database connections may be mismanaged, and troubleshooting issues can be difficult.
Putki’s RDBMS Impact transform helps solve this problem by providing automated SQL usage analysis, connection tracking, and schema impact assessment across projects.

This blog post explores how to use the RDBMS Impact transform effectively in Putki while ensuring proper pipeline execution.
Why Use the RDBMS Impact Transform?
The RDBMS Impact transform provides a comprehensive overview of SQL queries, database connections, and table interactions across an entire project.
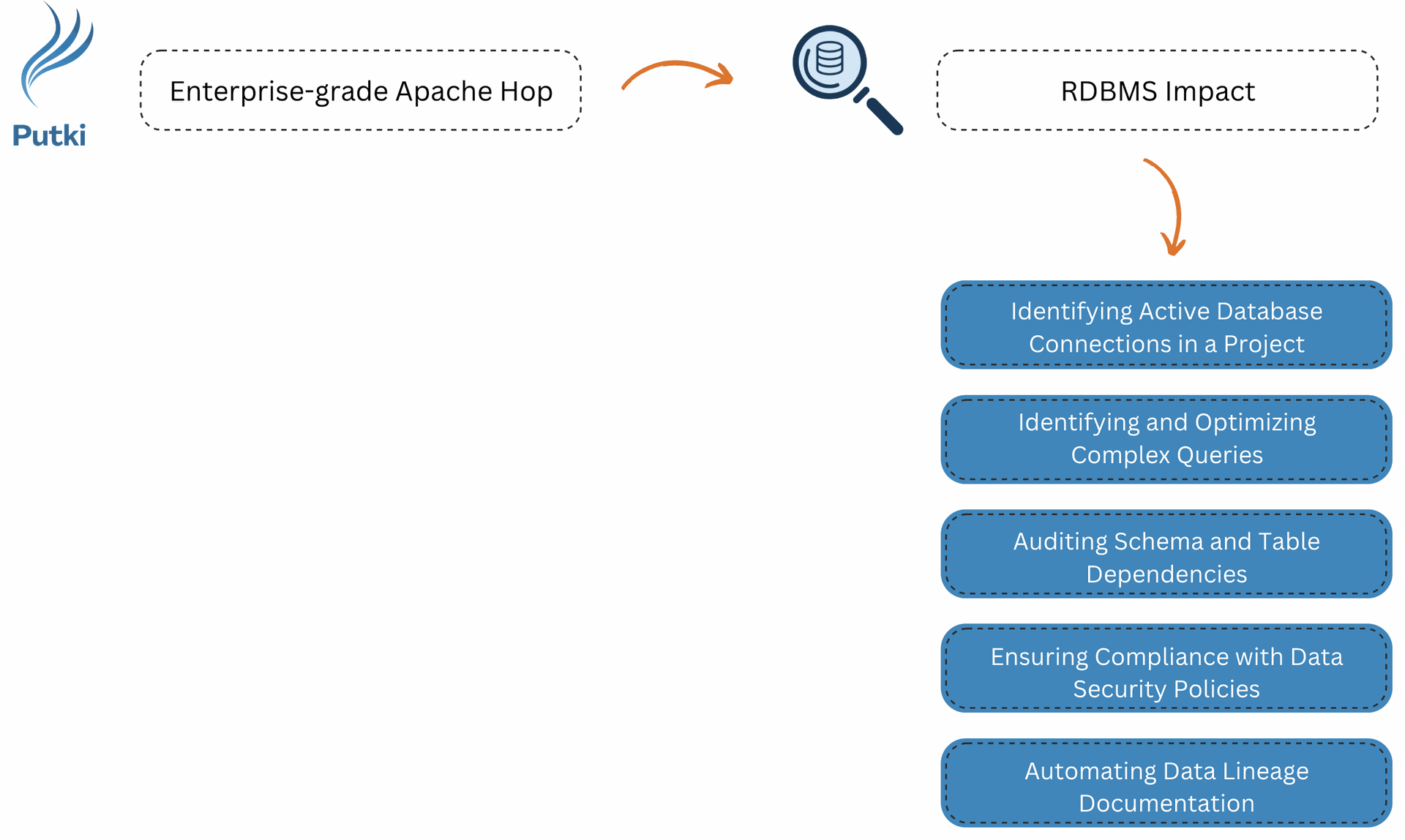
Use cases
1️⃣ Identifying Active Database Connections in a Project
Scenario:
Your data engineering team needs to audit all active database connections in an Apache Hop project. Over time, multiple connections have been configured, but it’s unclear which ones are actively in use.
How the RDBMS Impact Transform Helps:
- Scans all pipelines and workflows to list every database connection currently used.
- Helps identify unused connections, reducing security risks and improving resource management.
- Outputs a comprehensive report showing each connection, the related SQL queries, and their usage.
2️⃣ Identifying and Optimizing Complex Queries
Scenario:
Your team suspects that certain queries in your project are inefficient and slowing down the data pipelines. You need to identify complex queries (e.g., queries with multiple joins, subqueries, or aggregations) and optimize them.
How the RDBMS Impact Transform Helps:
- Extracts all SQL queries used across the project.
- Allows filtering to identify queries with multiple joins, subqueries, or aggregations.
- Helps the team prioritize query optimization by identifying the most frequently used complex queries.
3️⃣ Auditing Schema and Table Dependencies
Scenario:
Your company is migrating to a new data warehouse. Before making schema changes, the team needs to identify which pipelines rely on specific tables and columns to avoid breaking dependencies.
How the RDBMS Impact Transform Helps:
- Maps schema and table dependencies across all workflows and pipelines.
- Ensures no critical tables/columns are removed or altered before migration.
- Helps data governance teams document table usage.
4️⃣ Ensuring Compliance with Data Security Policies
Scenario:
Your organization follows strict data security and compliance regulations (e.g., GDPR, HIPAA). You need to track sensitive data usage and ensure that queries accessing personal or confidential data follow security guidelines.
How the RDBMS Impact Transform Helps:
- Identifies which queries access sensitive data fields (e.g., personal identifiers, financial records).
- Flags queries that may violate compliance rules, such as joining sensitive tables with non-secured ones.
- Provides an audit log of who is querying sensitive data and where it is used.
5️⃣ Automating Data Lineage Documentation
Scenario:
Your company needs to maintain accurate documentation of how data moves across your system, from ingestion to transformation and storage. Keeping this updated manually is inefficient and error-prone.
How the RDBMS Impact Transform Helps:
- Automatically extracts and maps data lineage by tracking how queries interact with tables and schemas.
- Documents which transforms, pipelines, and workflows modify data.
- Provides a structured report that business analysts and data stewards can use to understand data flow.
How to Use the RDBMS Impact Transform
The following example demonstrates the basic functionality of the RDBMS Impact transform using a small project. This is intended to show how the transform works in a simple scenario.
However, the possibilities extend far beyond this example. The RDBMS Impact transform can be used in larger, more complex projects, including:
- Analyzing multiple database connections simultaneously
- Processing large datasets
- Integrating with different data pipelines for advanced impact analysis
- Combining with the SQL Parser transform to extract schemas, tables, and columns from SQL queries for better metadata management and data lineage tracking

Step 1: Create a New Pipeline
- Open Putki.
- Create a new pipeline (e.g., rdbms-impact-analysis).
- Add the Generate Rows transform (Required: The RDBMS Impact transform needs an input row to execute).

- Configure Generate Rows:
- Number of rows: 1
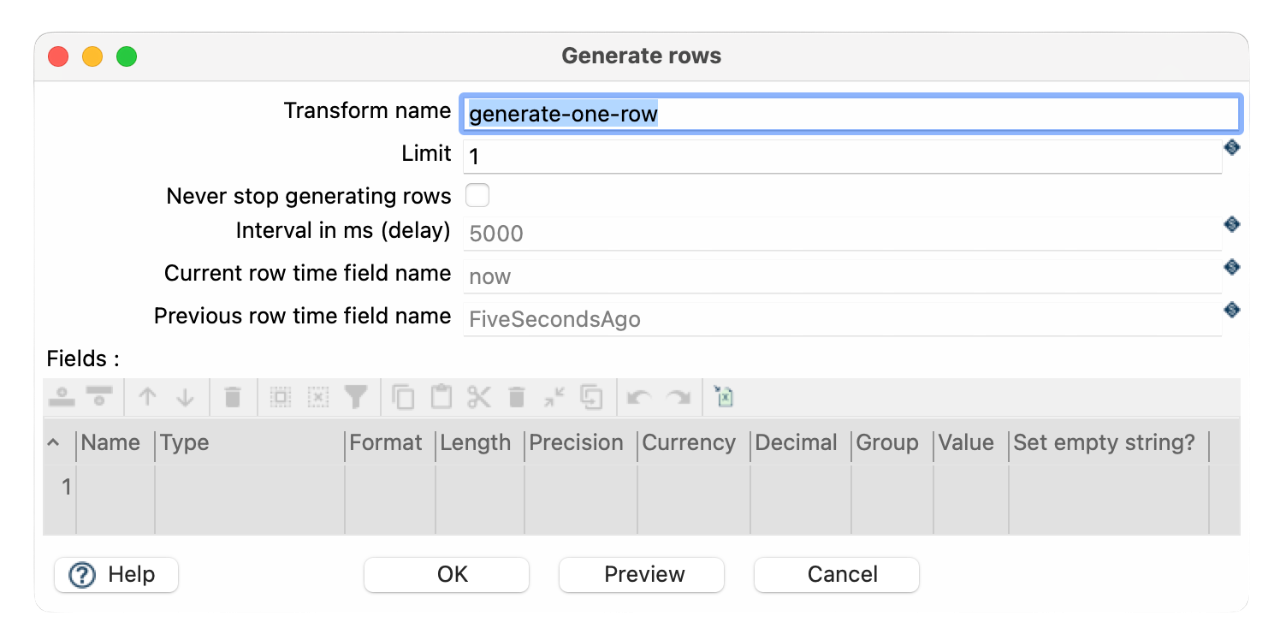
- Number of rows: 1
Step 2: Configure the RDBMS Impact Transform
- Add the RDBMS Impact transform to the pipeline.
- Connect Generate Rows → RDBMS Impact.

- Use the default configuration or customize the field names as needed.
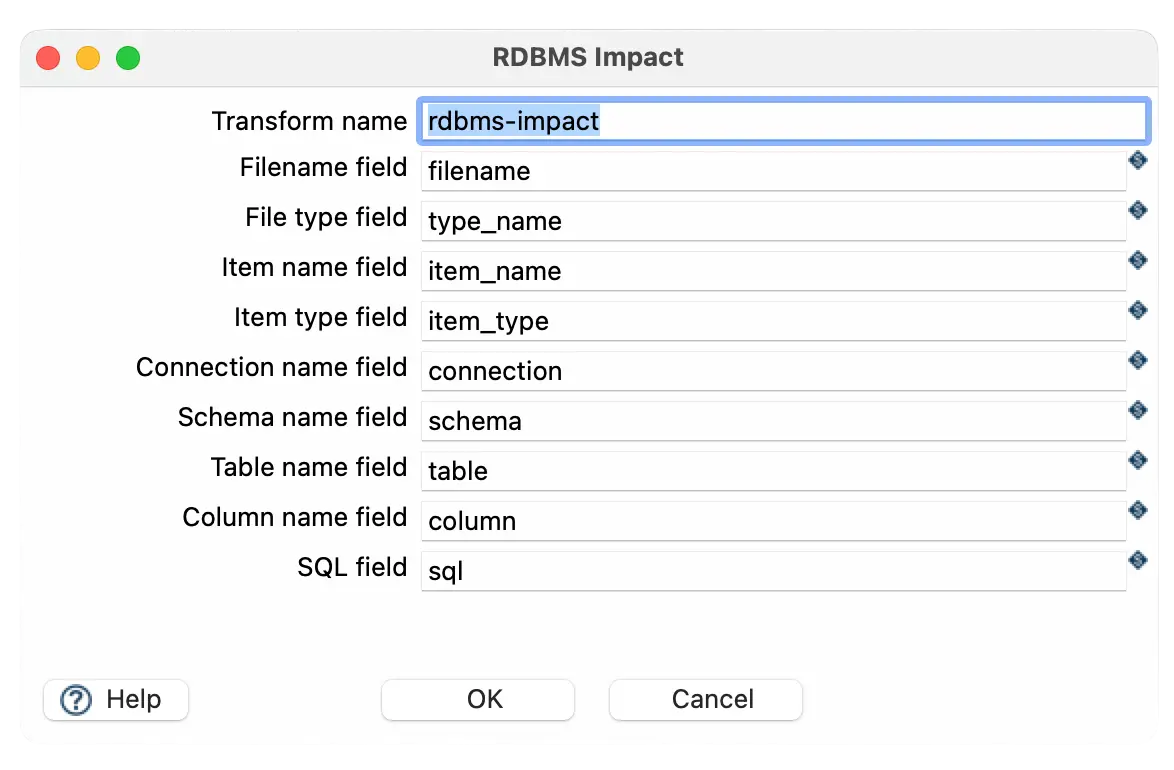
- The transform will automatically:
- Scan all SQL queries and database connections.
- Extract metadata such as filenames, schemas, tables, and columns.
Step 3: Filter Out Null Queries
- Add the Filter Rows transform.
- Connect RDBMS Impact → Filter Rows.

- Set a condition to filter out records where the SQL query field is null:
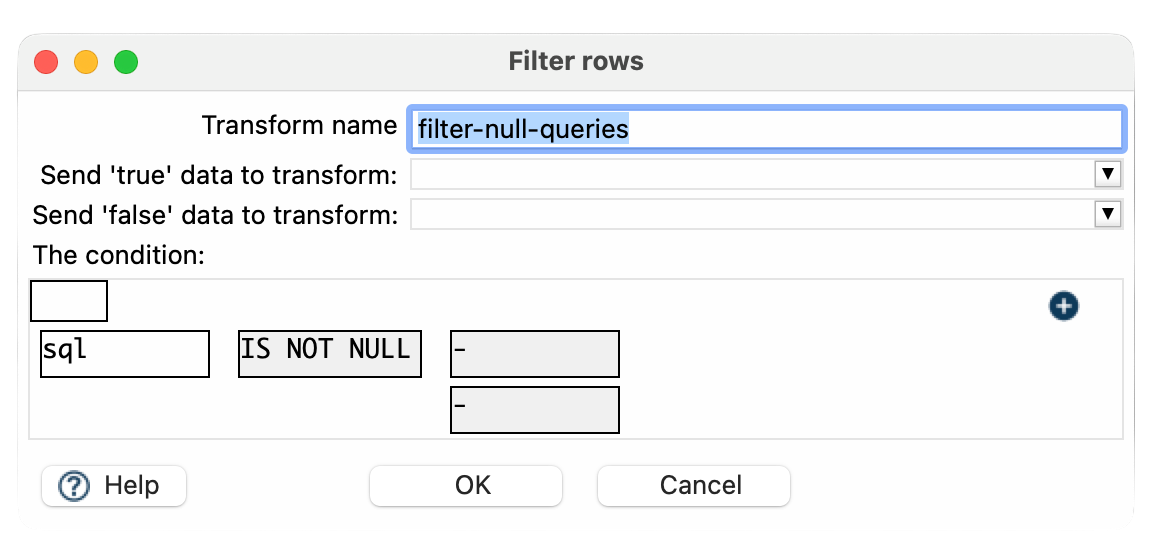
- Condition: sql IS NOT NULL
- This ensures only valid queries are written to the output.
Why Do We Filter Out Null Queries?
In this case, filtering out null queries ensures that we focus only on explicitly defined SQL queries within transformations like Table Input or actions like SQL Script. This helps us:
- Identify Potential Errors – Detect cases where SQL queries should be defined but are missing due to misconfigurations.
- Analyze Query Performance – Focus on actual SQL statements being executed to find inefficient or complex queries.
- Improve Database Governance – Ensure that all explicitly defined queries are reviewed for compliance and optimization.
Step 4: Save the Output
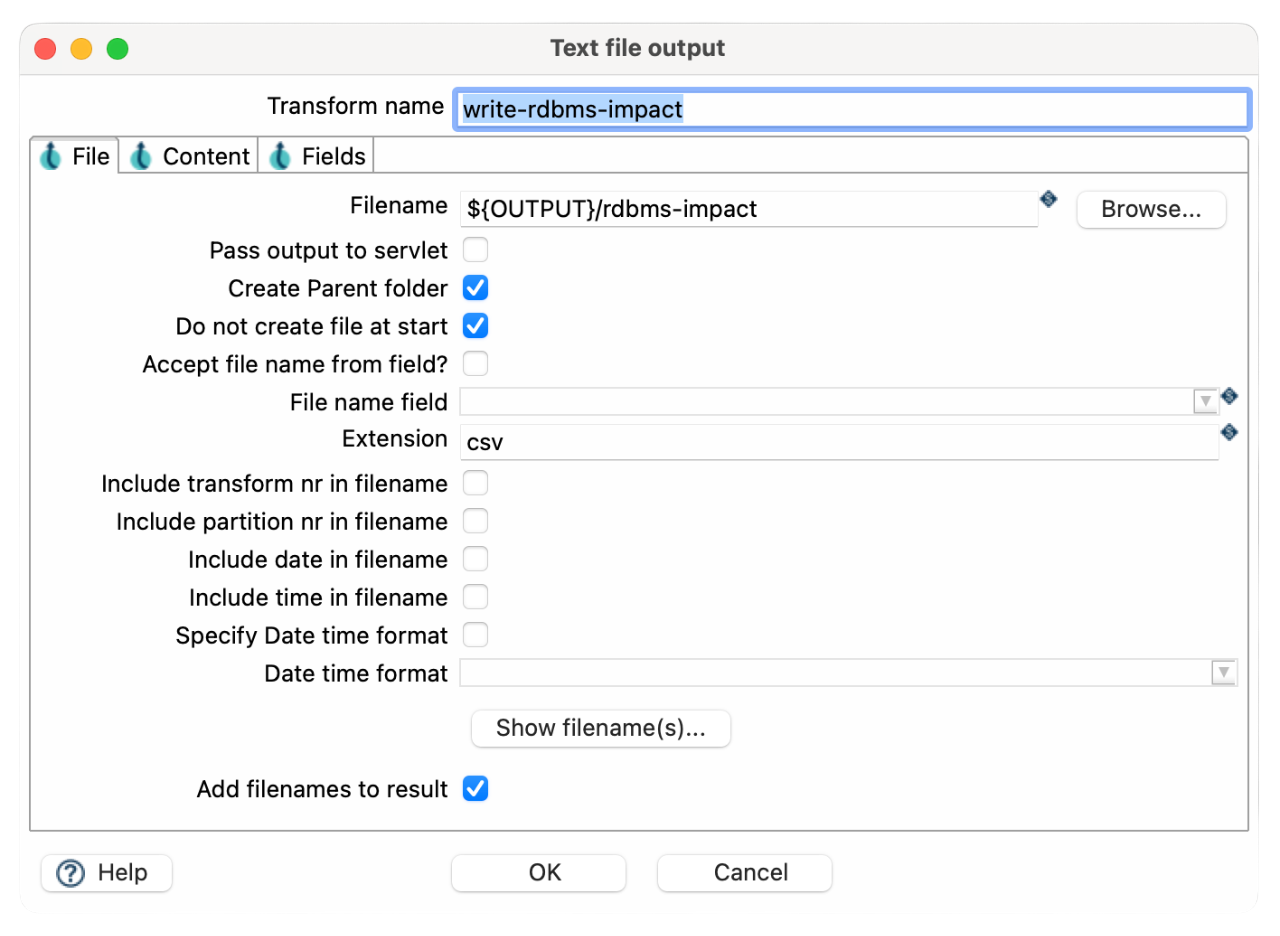
- Add the Text File Output transform.
- Connect Filter Rows → Text File Output.
- Configure output settings:
- Filename: rdbms-impact-report.csv
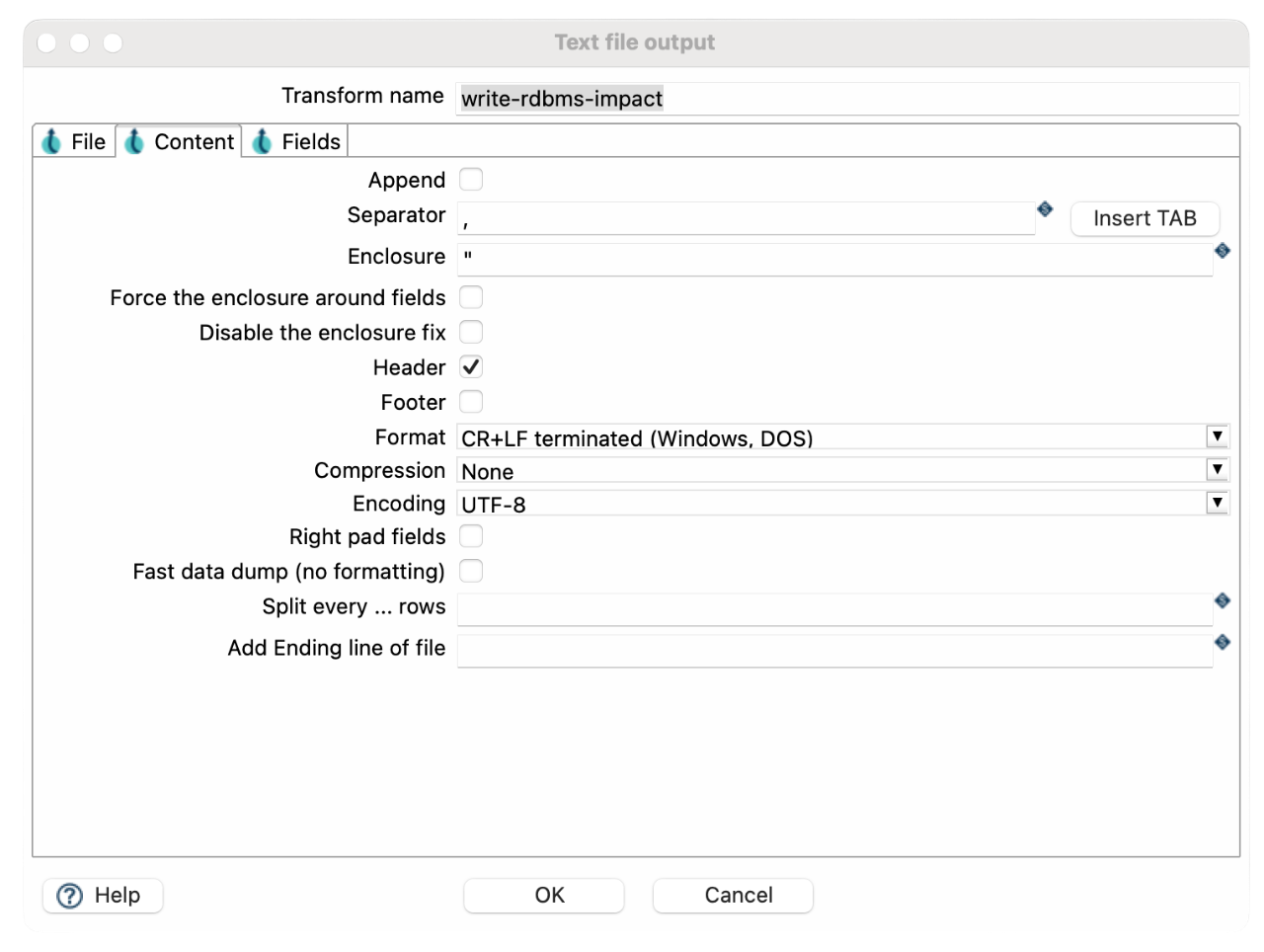
- Delimiter: , (comma-separated)
- Include Header Row: ✔️ Enabled
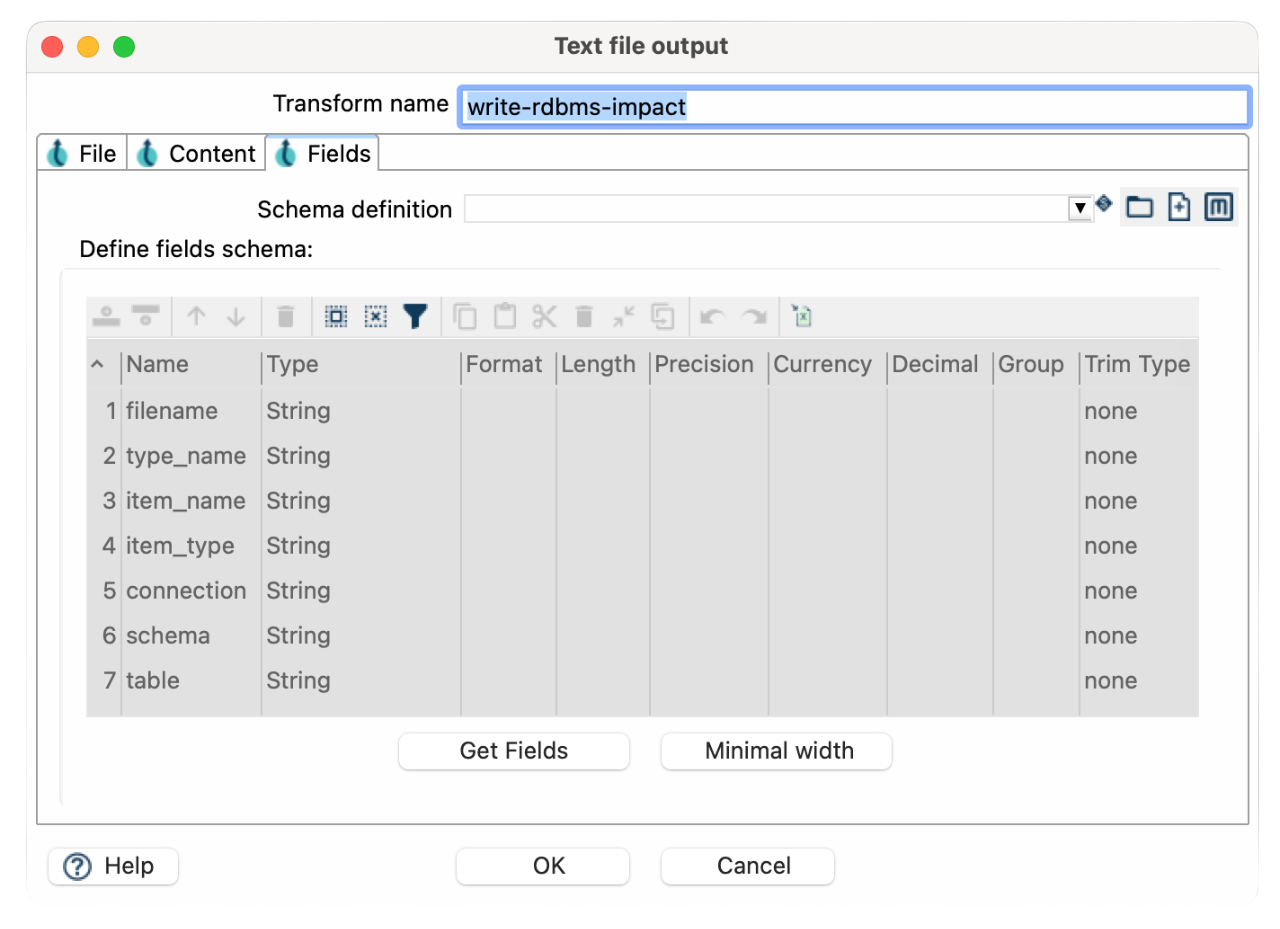
- Filename: rdbms-impact-report.csv
- Map the output fields from RDBMS Impact to the Text File Output to ensure accurate reporting.
Step 5: Execute the Pipeline
- Run the rdbms-impact-analysis pipeline.
- The RDBMS Impact transform will scan all pipelines and workflows in the project.
- After execution, review the generated CSV report to ensure all SQL queries, database connections, schemas, tables, and columns are accurately captured.
Sample Output
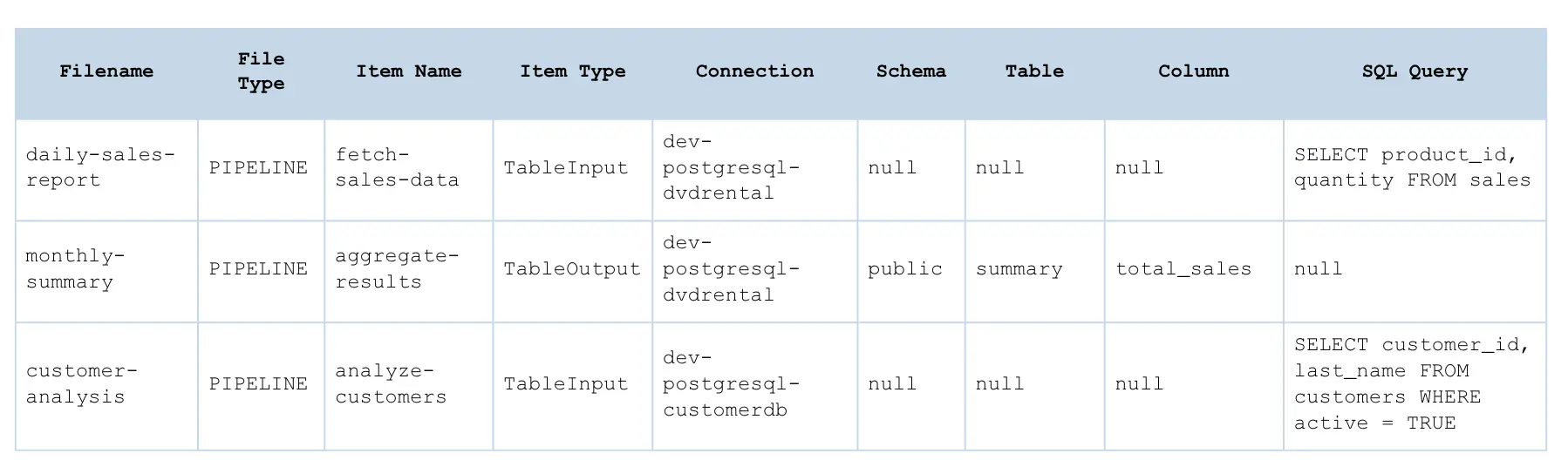
Note that certain fields can be null in the following cases:
- Connection name field: This can be null if a connection is expected but not selected (e.g., in a workflow action like Check Connection where the connection hasn’t been specified). This also helps identify potential errors in the code or highlight unused files in the project.
- Schema name field: For transformations like Table Input that rely on a query but don’t require a schema field, this will remain empty. However, for transformations like Table Output, the schema might be specified.
- Table name field: Similar to Schema—can be null depending on the transformation.
- Column name field: Follows the same logic as Schema and Table fields.
Key Benefits of Using the RDBMS Impact Transform
- Ensures Comprehensive SQL Analysis – Scans all pipelines automatically for SQL queries and database connections.
- Eliminates Manual Effort – No need for tedious manual tracking of SQL statements.
- Improves Database Governance – Enhances visibility into SQL usage and database dependencies.
- Optimizes Database Resource Management – Helps eliminate unused or redundant database connections.
Conclusion
By leveraging Putki’s RDBMS Impact transform, data engineers can:
- Efficiently document SQL queries
- Manage database connections with better visibility
- Maintain governance across projects
- Automate SQL documentation
Using Generate Rows ensures the pipeline executes correctly, while filtering null queries refines the final output.
Next Steps
- Experiment with different database configurations.
- Explore advanced filtering options for refining query impact analysis.
- Share your experience and best practices with Putki’s RDBMS Impact transform!
Don't miss the video below for a step-by-step walkthrough.
Ready to optimize your database tracking?
Start with Putki today!