
We're excited to announce the release of Putki 2026.03, our latest enterprise edition built on the brand-new Apache Hop 2.17.
Apache Hop 2.17 is the result of three months of intensive collaboration, testing, and refinement by the open-source community. It closed 194 tickets across 18 contributors, more than double the output of the previous release. It's a release that balances major new integrations with meaningful improvements to how data teams actually work day to day.
At know.bi, we're proud to have contributed directly to this release. We believe that the strength of Putki starts with the strength of Apache Hop, and 2.17 is a clear demonstration of what a focused, experienced open-source community can deliver when it aligns around solving real problems.
With Putki 2026.03, you get everything Apache Hop 2.17 delivers, plus our full layer of enterprise-grade integrations, a curated distribution, and professional support backed by SLAs.
What's new in Apache Hop 2.17
MongoDB and Atlas support
Many organizations are shifting critical workloads to document databases, and Apache Hop 2.17 responds directly to that trend. Hop 2.17 now includes full support for MongoDB Atlas clusters, meaning your data teams can integrate managed MongoDB environments without wrestling with connection pooling, SSL/TLS configuration, or cluster discovery.
In practice, this means automatic cluster detection for Atlas deployments, simplified credential management for cloud-hosted MongoDB, and built-in resilience for semi-structured and fast-changing datasets. For organizations with hybrid cloud architectures or those modernizing legacy data systems, this removes a significant friction point in pipeline development.
Neo4j 5.x compatibility
Apache Hop 2.17 upgrades to full Neo4j 5.x compatibility, ensuring that graph-based pipelines remain performant and compatible with the latest Neo4j deployments. This isn't just a version bump. It signals a commitment to evolving integrations alongside the technologies your data teams depend on.
A redesigned interface built for productivity
The largest set of improvements in Apache Hop 2.17 focuses on how data engineers actually spend their day: building pipelines. The interface has been redesigned to reduce context-switching and cognitive load.
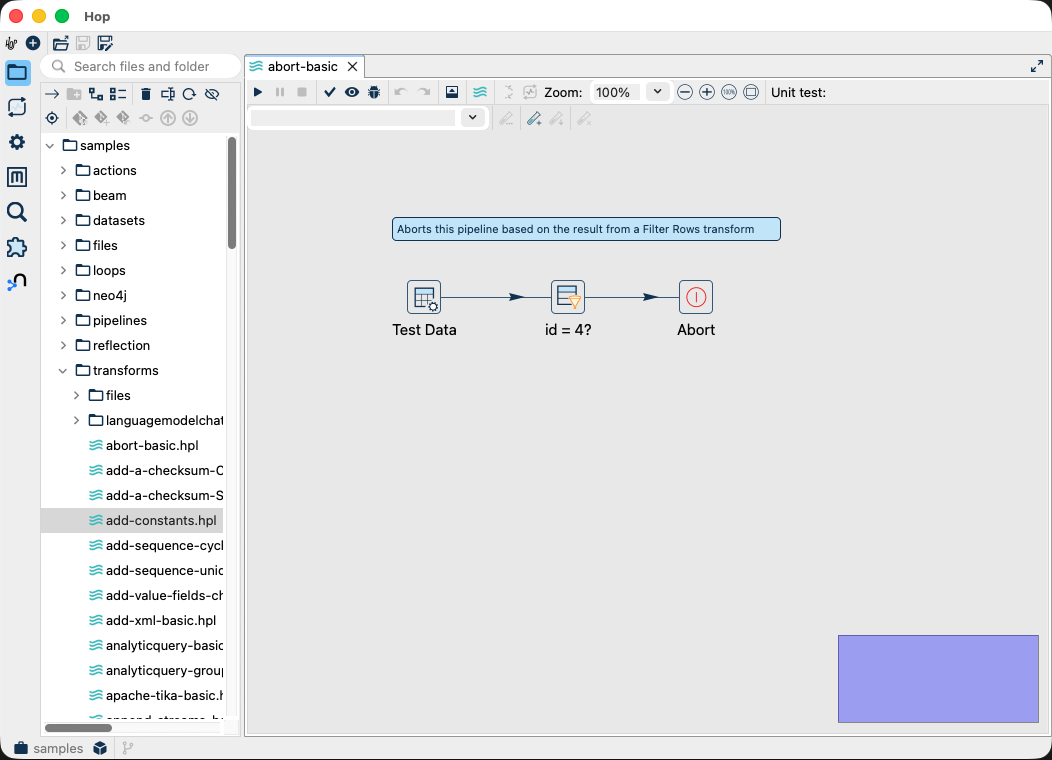
The File Explorer and Designer are now unified into a single workspace. You can browse project files while building pipelines, search across all project assets without leaving the editor, and switch between files without losing your working context. For teams managing large projects with many pipelines and workflows, this alone is a meaningful productivity gain.
The properties panel has also been overhauled. Every option has been reviewed, renamed, and reorganized, resulting in a cleaner interface with better discoverability. New keyboard shortcut overlays help both new and experienced users work faster.
Error visibility in logs
When pipelines fail in production, every minute of diagnosis time has a cost. Apache Hop 2.17 now highlights errors in red across logs and console output, with automatic detection for color support. Combined with improved logging infrastructure, this straightforward visual change makes it noticeably faster to identify and resolve production issues.
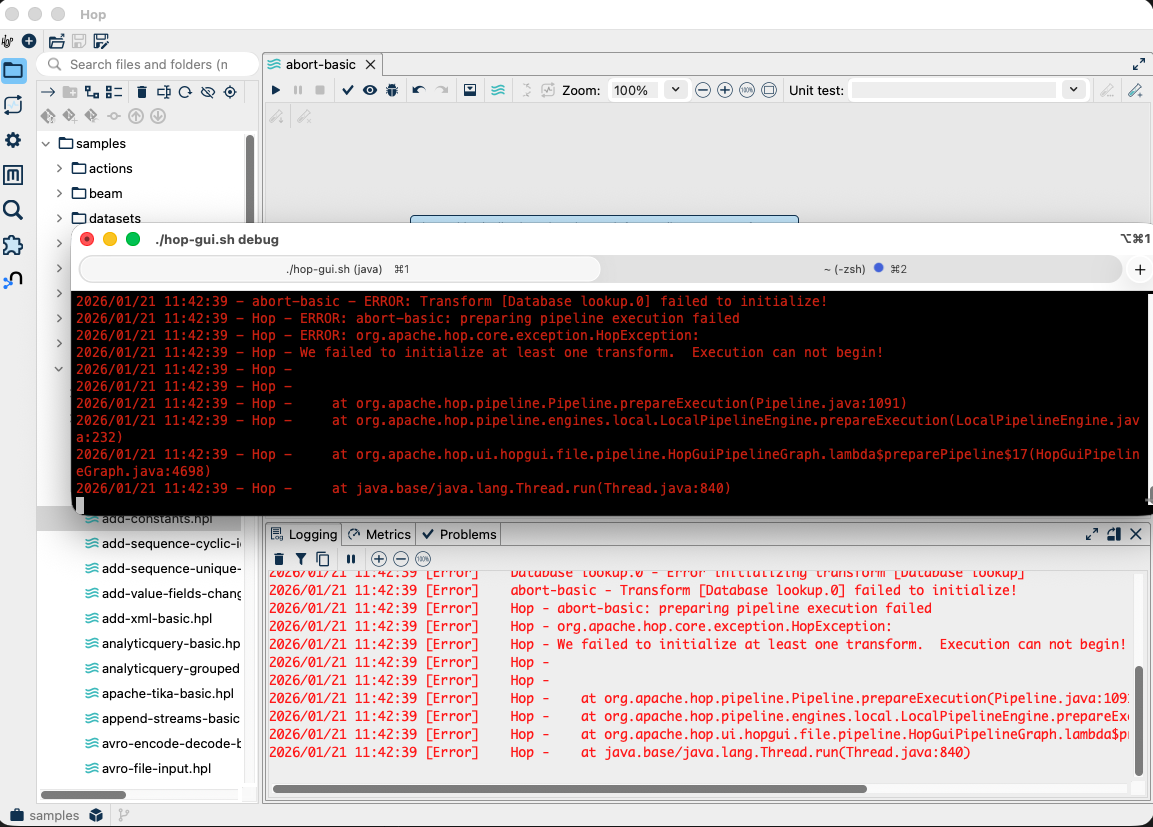
Git integration that works at your pace
Version control is a critical part of any production data platform, and Apache Hop 2.17 delivers three meaningful Git improvements. Repository detection now works when your Git repo sits above your Hop project folder, a common real-world setup that previously caused friction. Modified files already under version control are staged automatically. And the Git information panel now shows diffs with color highlighting, making code review faster and more intuitive.
Stability and security improvements
Behind the scenes, Apache Hop 2.17 includes significant improvements that matter most in production. Metadata Injection reliability has been improved, reducing runtime inconsistencies when using variable injection in complex pipelines. Apache Beam has been upgraded to 2.70.0, Neo4j to 5.x, and numerous security patches have been applied throughout. Azure Blob Storage now supports managed identity with root folder browsing, improving cloud-native deployment scenarios. And a significant performance issue in the Filter Rows transform when comparing static values has been resolved, a fix with a direct impact on pipeline throughput in production.
Enterprise integrations in Putki 2026.03
Putki extends Apache Hop with a curated set of enterprise integrations covering documentation, observability, governance, and business system connectivity. Every integration is fully supported and battle-tested in production environments.
Autodoc: Generate complete technical documentation for your Hop projects in PDF or HTML format, automatically. Autodoc is ideal for compliance requirements, knowledge sharing across teams, and onboarding new developers. Instead of maintaining documentation manually and watching it drift from reality, Autodoc keeps it in sync with your actual pipelines and workflows.
Chat: Connect Apache Hop with your communication stack. Get real-time alerts when pipelines succeed, fail, or cross thresholds, and enable collaboration directly in your existing chat tools. If your team uses Slack, Chat brings your data operations into the conversation, literally.
Flyway Migrate: Run database schema migrations directly within Hop workflows, without managing a separate Flyway setup. Flyway Migrate brings schema lifecycle management into your data pipelines, enabling controlled, auditable database changes as part of your broader data orchestration. For teams operating in regulated environments or managing multiple database environments, this is a real operational improvement.
RDBMS Impact: Understand the full impact of SQL operations across your pipelines and workflows. RDBMS Impact gives you visibility into which pipelines touch which tables, which queries are running against which databases, and what the downstream effect of a schema change might be. For data teams managing complex multi-system environments, this kind of operational intelligence matters.
SQL Parser: Extract and analyze SQL statements from fields in your data streams at scale. SQL Parser makes it easier to validate, refactor, or monitor SQL embedded in your data, a capability that becomes essential when working with dynamic query generation, legacy system migrations, or complex analytics pipelines.
HubSpot Input: Pull data from HubSpot with full schema and metadata support, enabling reliable CRM data integration as part of your broader pipelines. Whether you're syncing contacts, deals, or engagement data, HubSpot Input gives you a supported, maintained connector rather than something you have to build and own yourself.
Shopify Input: Integrate Shopify data directly into your pipelines. From orders and products to customers and inventory, Shopify Input provides a reliable foundation for ecommerce data integration, fully supported and maintained by know.bi.
Full Odoo connectivity
Putki 2026.03 ships with the most comprehensive Odoo integration available in any data platform. The full Odoo connector suite includes:
- Odoo Input: Read any Odoo data model into your pipelines
- Odoo Insert: Write new records to Odoo
- Odoo Update: Update existing Odoo records
- Odoo Upsert: Insert or update in a single operation
- Odoo Delete: Remove records from Odoo as part of automated workflows
- Odoo Helpdesk Input: Dedicated connector for Odoo helpdesk and ticketing data
- Odoo Website Page Update: Manage Odoo web content programmatically as part of your data workflows
For companies running Odoo as their ERP backbone, this depth of integration means you can build reliable, bidirectional data flows between Odoo and the rest of your data stack, without fragile custom scripts or expensive middleware.
A curated distribution, ready for your team
Apache Hop is a vibrant, fast-moving open-source project, and that's genuinely one of its strengths. Getting the most out of it, though, takes time: understanding the architecture, choosing the right setup, configuring it correctly, and building the operational practices around it. That investment is real, and it sits with your team.
Putki is designed to reduce that investment without taking away the flexibility. We ship a curated distribution of Apache Hop that reflects years of production experience, with sensible defaults, a focused plugin set, and deployment guidance built around European infrastructure and data sovereignty requirements. Security updates and patch releases are delivered by know.bi on a structured schedule. And our documentation, knowledge base, and support team mean you're not figuring things out from scratch or waiting on community forums.
Apache Hop gives you a powerful foundation. Putki gets you there faster, with less risk, and with someone to call when it matters.
Enterprise support
Putki is more than enterprise integrations and a curated distribution, it's about confidence in production. Our support plans are designed for teams running Apache Hop in mission-critical environments, with guaranteed response times, expert guidance, and a single point of contact who understands your environment.
From business-hours CET support with security updates at the Basic tier, to priority bug fixes and faster response times at Professional, to fully SLA-backed dedicated technical advisory at Enterprise, we have a plan that fits your team's needs and risk tolerance.
Optional add-ons include extended SLA and support hours, onboarding and training packages, deployment optimization consulting, and premium connector modules for advanced Odoo, Shopify, and HubSpot use cases.
Try Putki 2026.03 in minutes
Putki 2026.03 ships a ready-to-run Docker Compose setup that brings up the full Putki stack with a single command, web studio, execution engine, scheduler, and monitoring dashboard, all pre-configured.
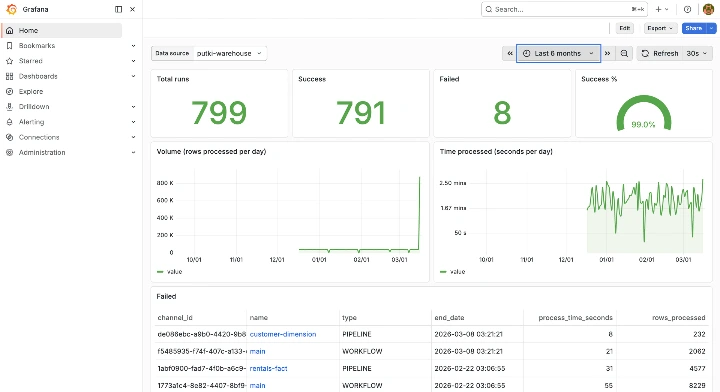
Putki comes with a built-in Grafana monitoring dashboard that gives you a live view of execution health across your entire environment, success rates, error tracking, rows processed, and execution times, all in one place.
Get started with Putki 2026.03
Putki 2026.03 is available now.
If you're scaling a growing data team across multiple projects and environments, or running mission-critical workloads that need full governance, lineage, and SLA-backed support, Putki 2026.03 gives you the platform, the enterprise integrations, and the people to do it with confidence.
Learn more and find the support plan that fits your team: Putki Pricing Plans