
At the core of Apache Hop lies the concept of pipeline execution and data movements, which play a crucial role in orchestrating complex data workflows. In this blog post, we delve into the fundamentals of pipeline execution and explore how understanding data movements can unlock new levels of efficiency in your data processing tasks.
One of the key concepts that newcomers to Apache Hop often encounter is the parallel execution of pipelines and the sequential execution of workflows.
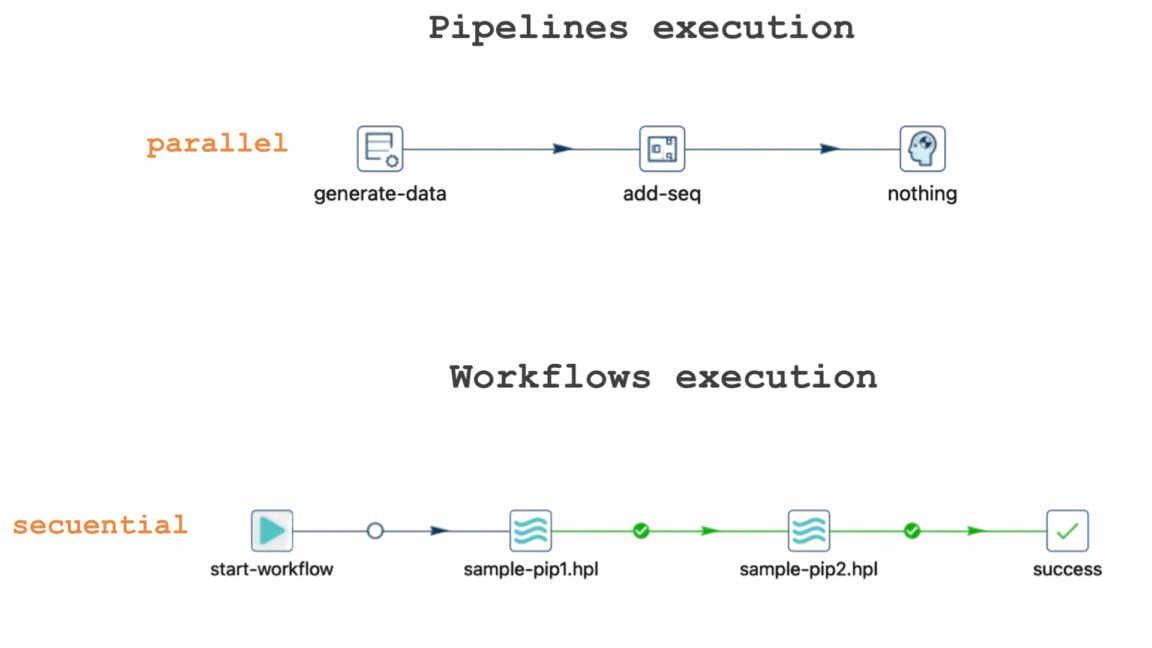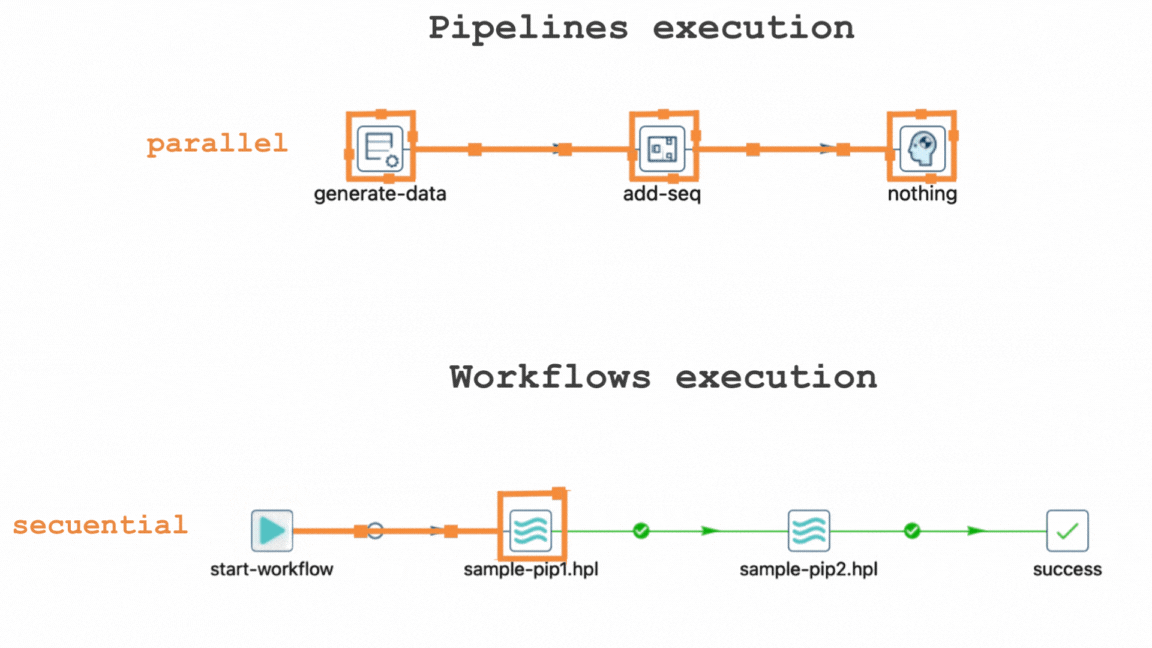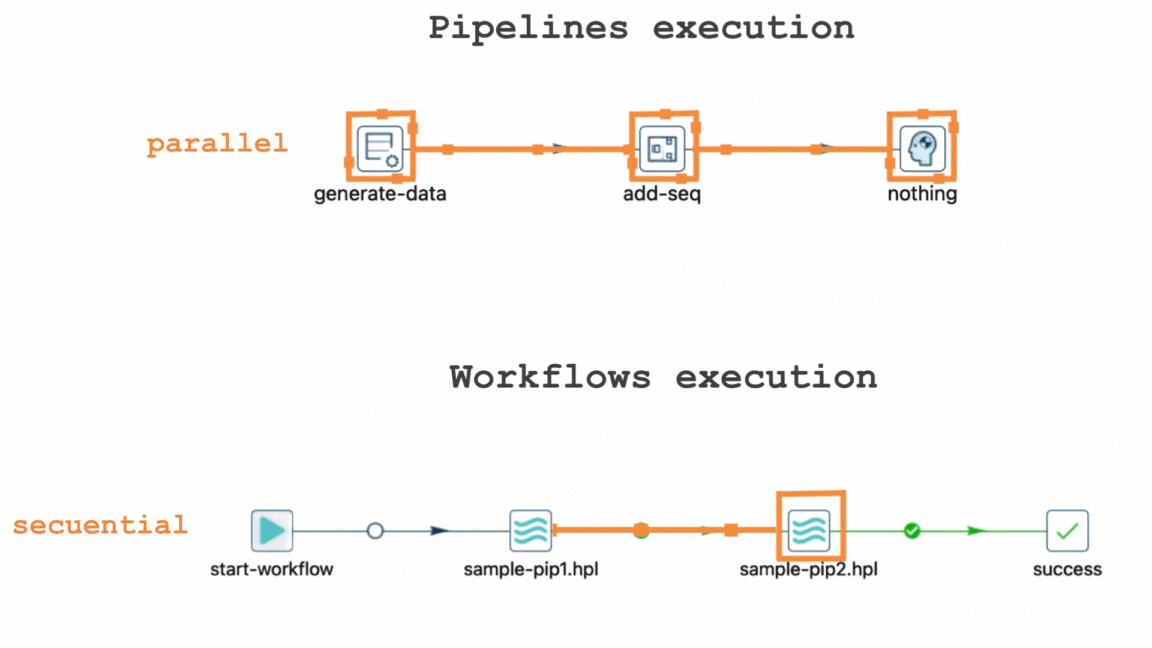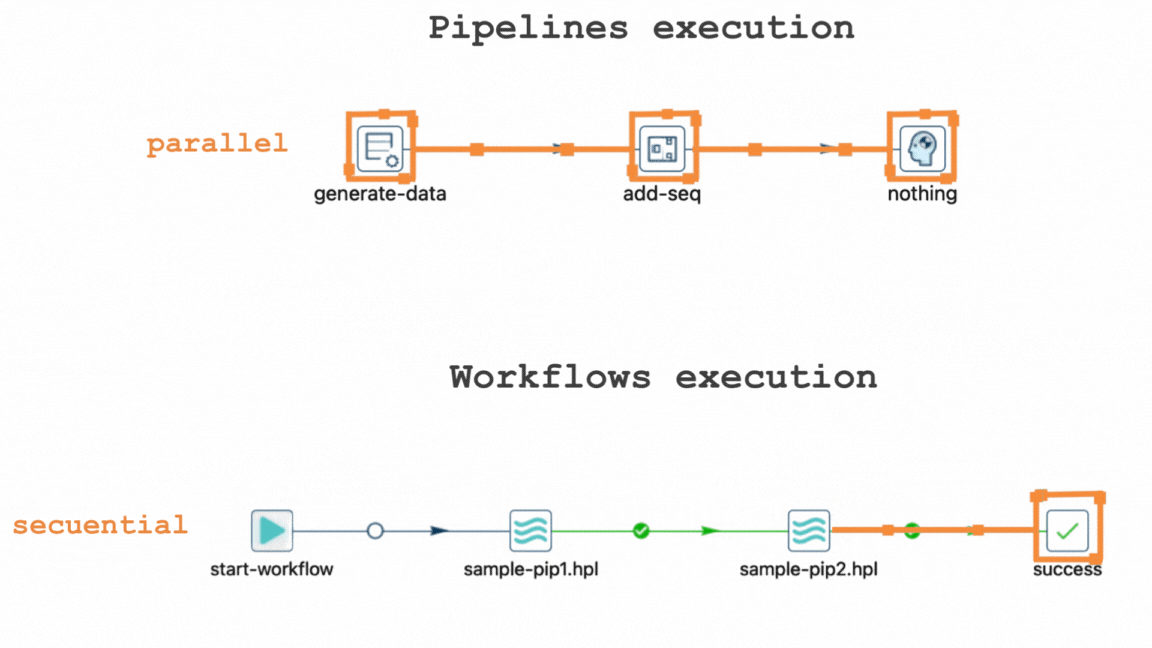
In Apache Hop, pipelines are designed to execute data transforms in parallel, allowing multiple operations to be performed simultaneously. This parallel processing not only accelerates data processing but also enhances overall efficiency, making it a fundamental aspect of Apache Hop's design philosophy. On the other hand, workflows progress sequentially, ensuring that actions occur in a predetermined order to maintain dependencies and data integrity.
However, this behavior represents the default or standard approach. In this article, we'll explore different scenarios that may occur during pipeline execution.
For instance, when linking transforms in a pipeline, users may come across data movement options like "Distribute" and "Copy." These methods dictate how data flows through the pipeline and can greatly influence implementation. By grasping the consequences of each method and choosing the right one, you can optimize your pipelines for peak performance and effectively debug your data flows.
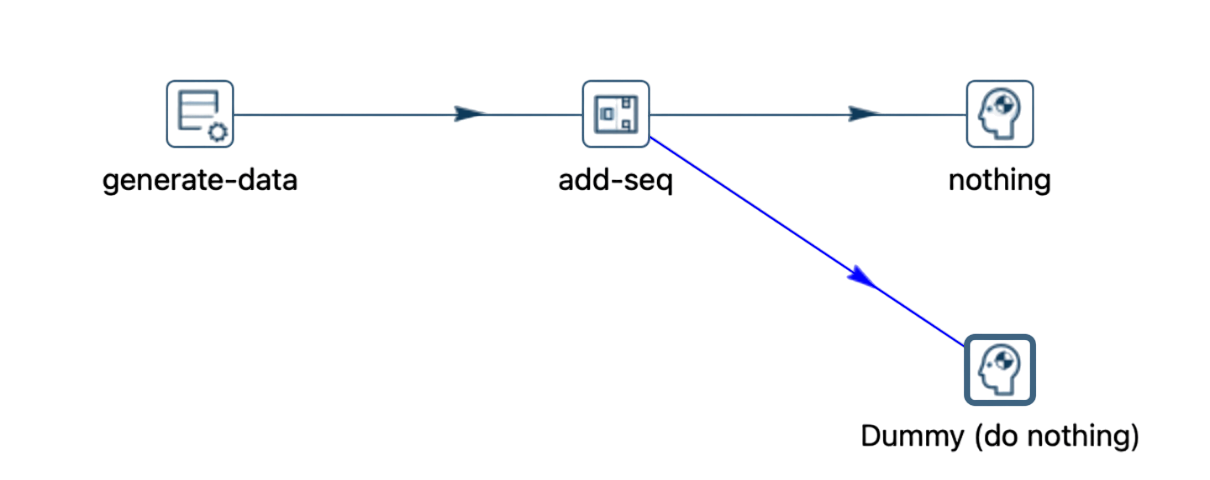
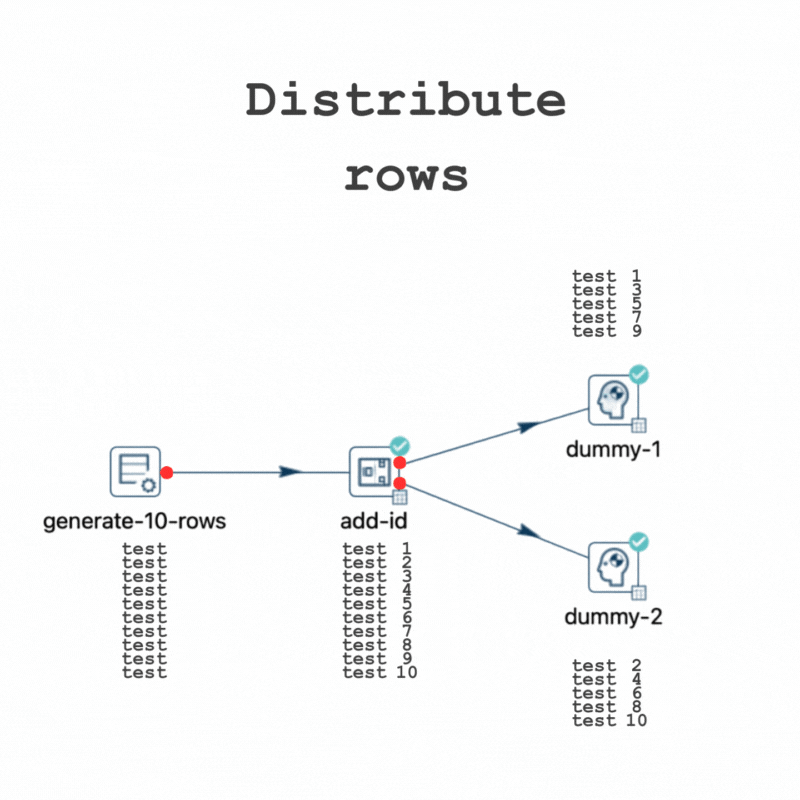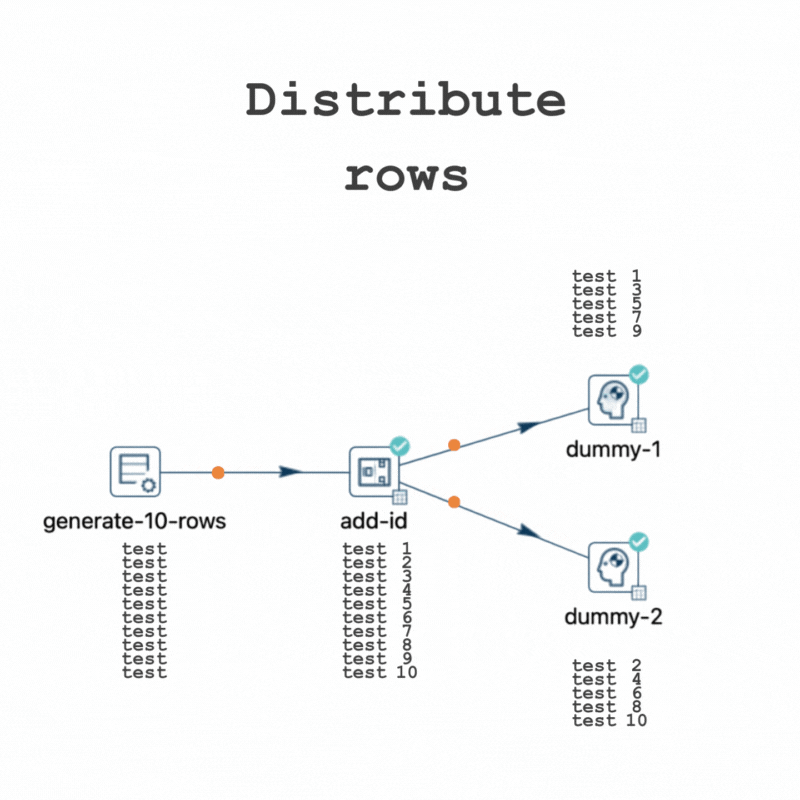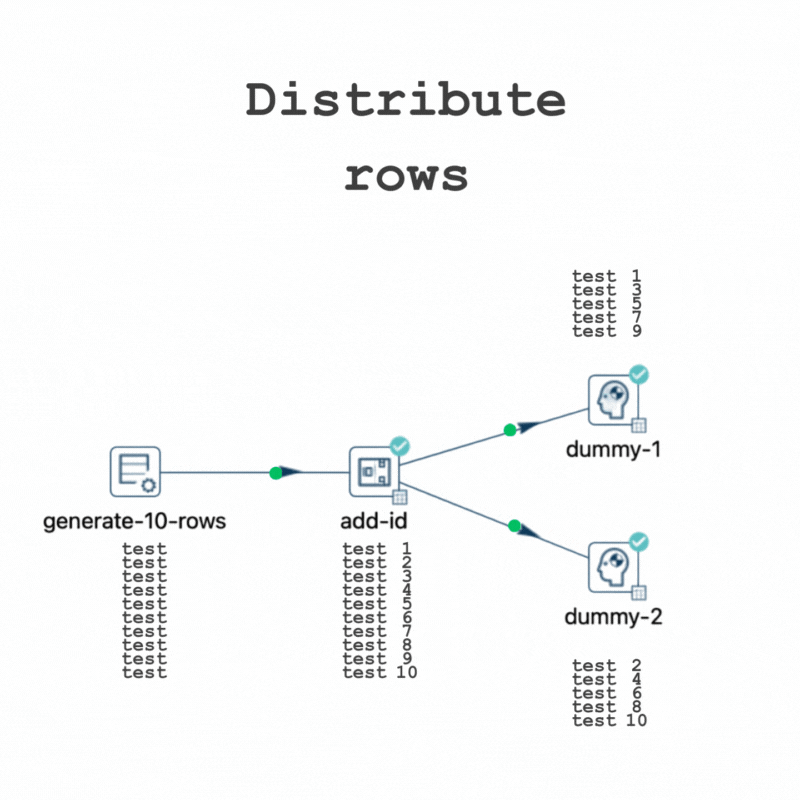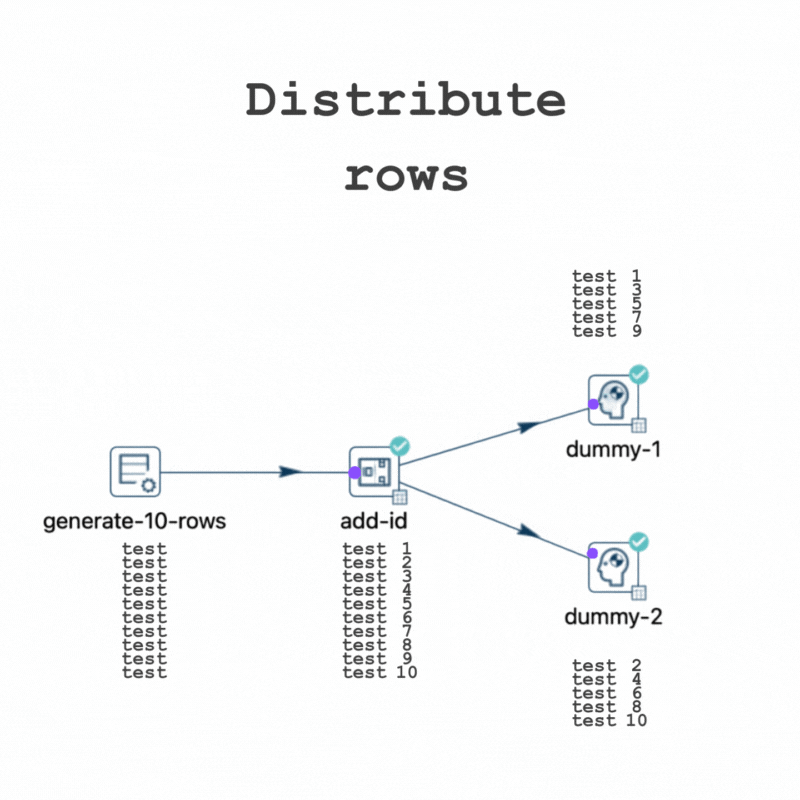
To illustrate this concept, consider the following scenario, where a simplified pipeline generates 10 rows and subsequently adds a sequence number to each.

The "Add sequence" transform is linked to a "Dummy" transform, which only receives the data without performing any additional actions.
Consider a scenario where you want to link the "Add sequence" transform to two transforms instead of just one. If you attempt to connect a second "Dummy" transform, a warning message will appear.
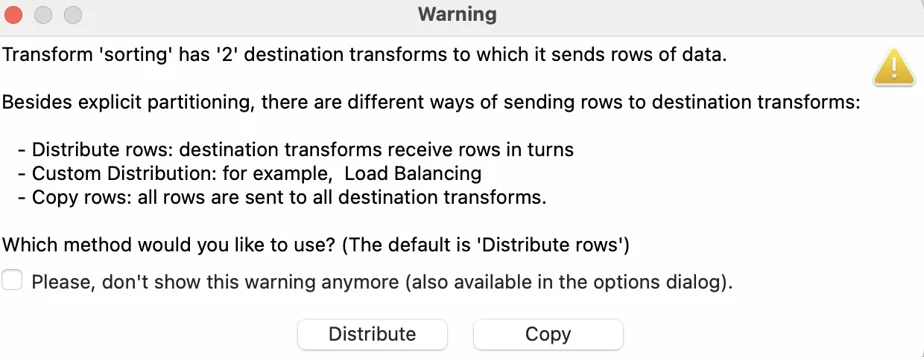
Let's pause for a moment to review this message. We'll explore explicit partitions and load balancing in a future post.
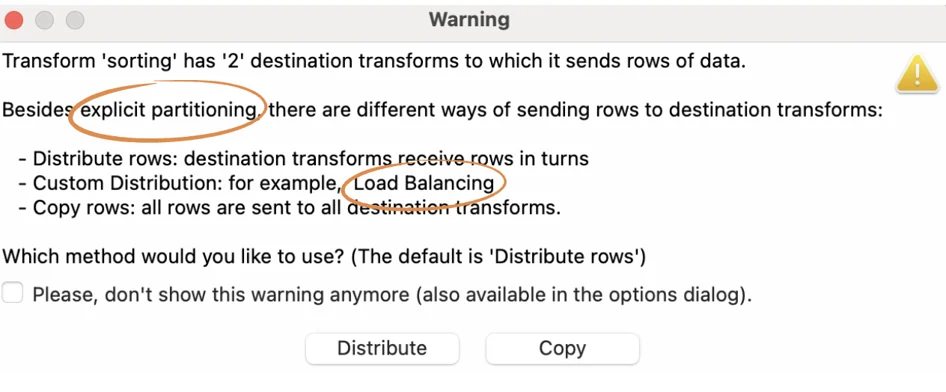
It highlights that when using the "Distribute rows" method, destination transforms receive rows in turns, while with the "Copy rows" method, all rows are sent to every destination transform.

So, what does this mean? Let's first select the distribution method.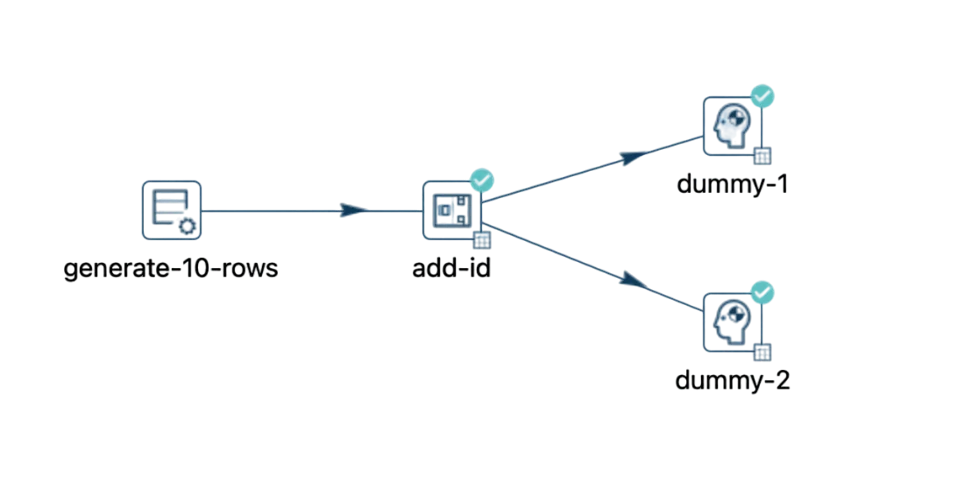
In this pipeline, for instance, out of 10 rows, 5 will be directed to "dummy-1" and the other 5 to "dummy-2".
Although this pipeline speeds up due to the data volume, testing it with 10,000,000 rows reveals significant data movements in the execution metrics.
Focusing on the execution metrics for the Add sequence transform, we observe that it doesn't receive all 10,000,000 rows at once.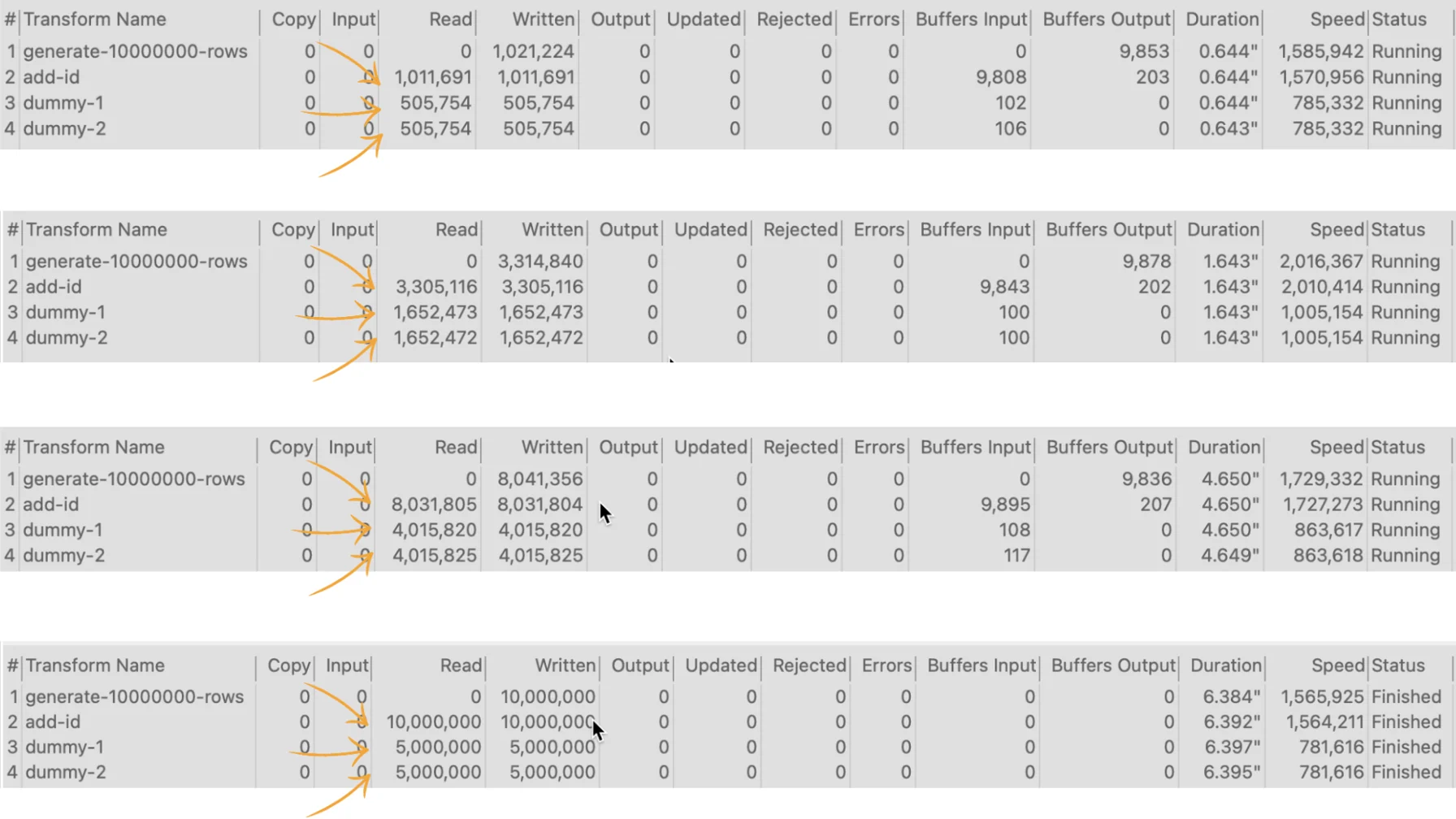
Instead, it processes a portion of the rows, adds the identifier, and distributes them to "dummy-1" and "dummy-2" until all rows are processed.
This illustrates how pipelines inherently execute in parallel by default.
Now, returning to the original scenario but opting for the "Copy rows" option, each connection from the "Add sequence" transform displays a copy icon.
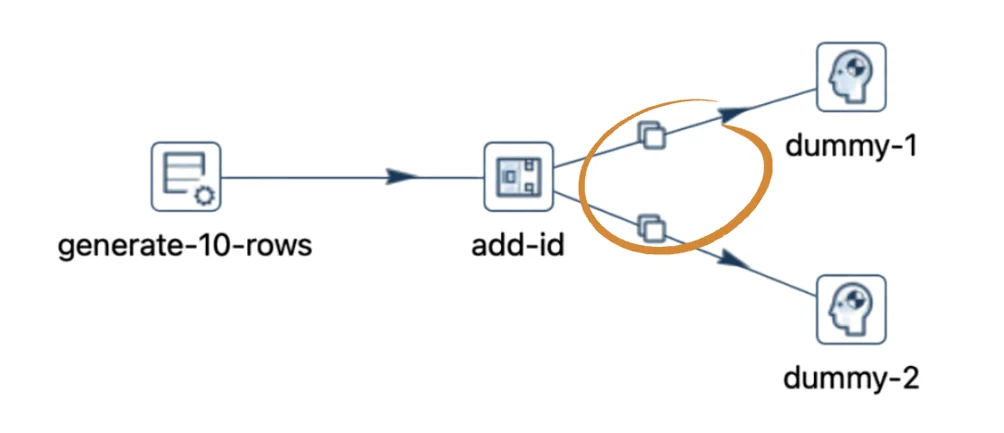
Consequently, all 10 rows are sent to both "dummy-1" and "dummy-2" during execution.
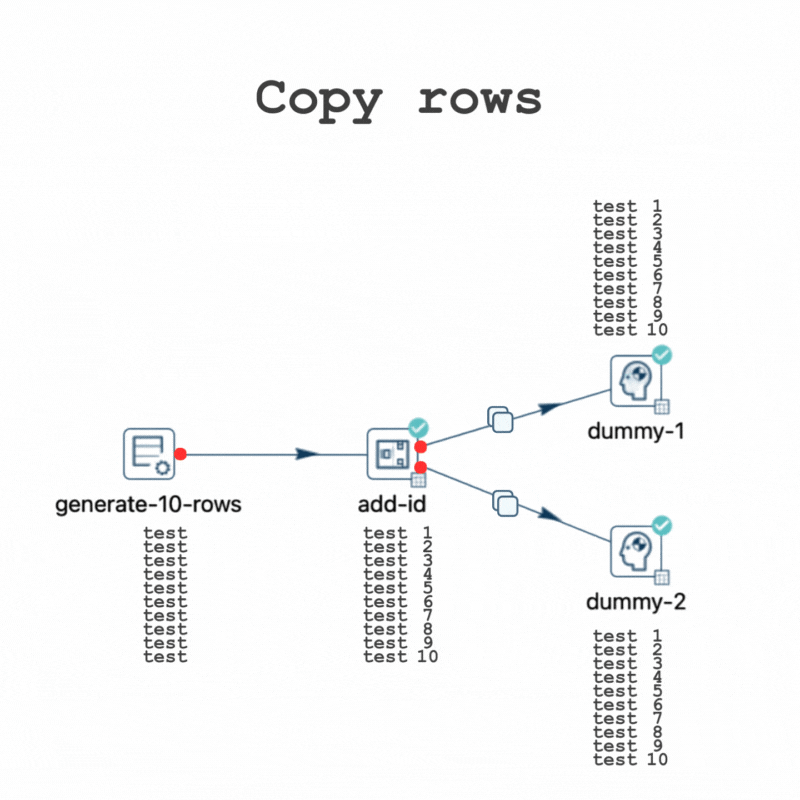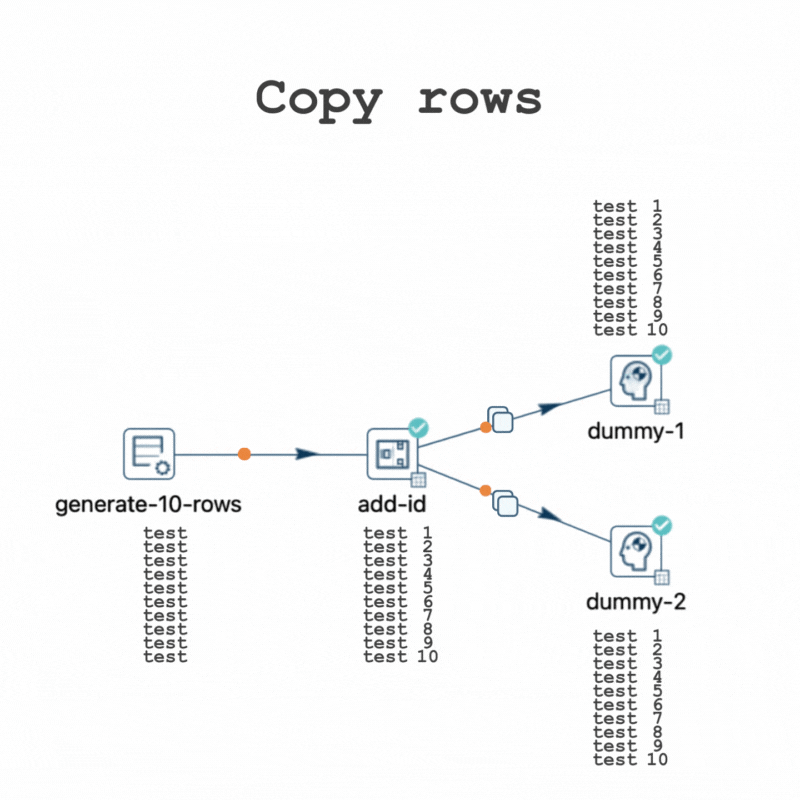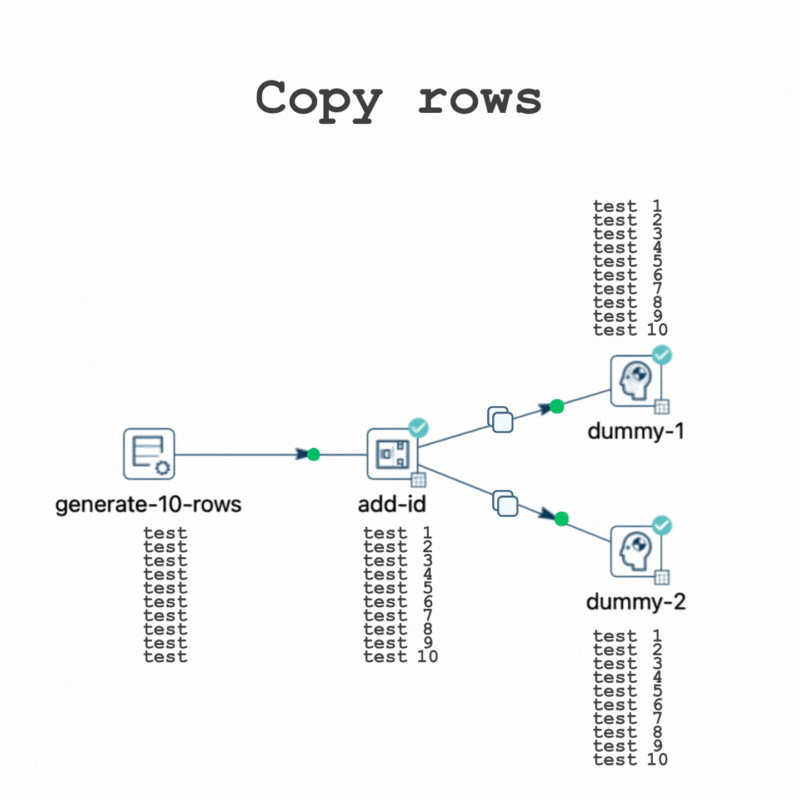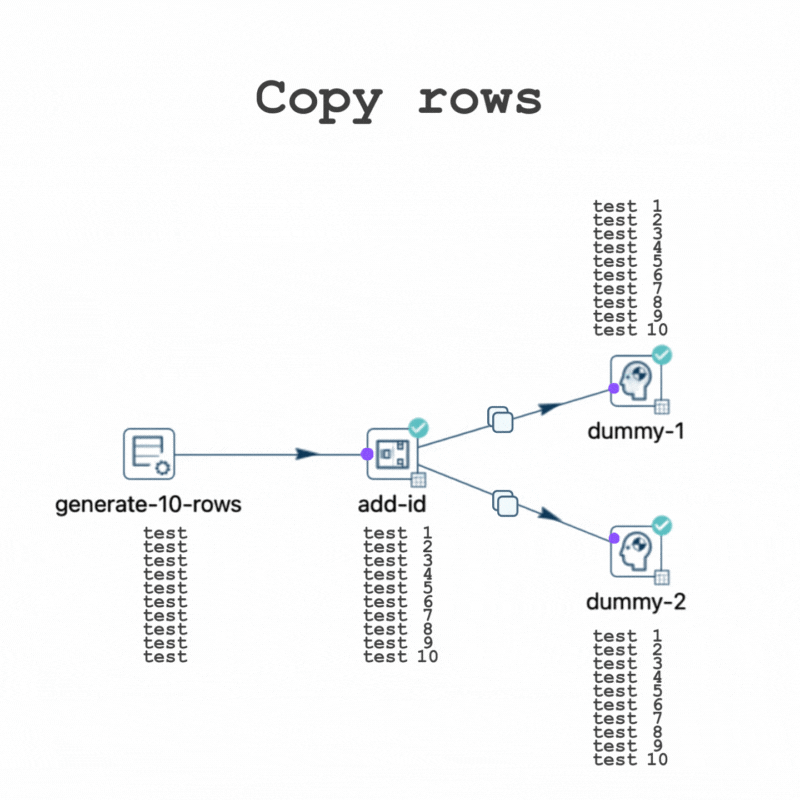
While this pipeline also performs fast due to the data volume, testing it with 10,000,000 rows shows the data movements in the execution metrics.
Now focus on the amount of rows received by the Dummy transforms.
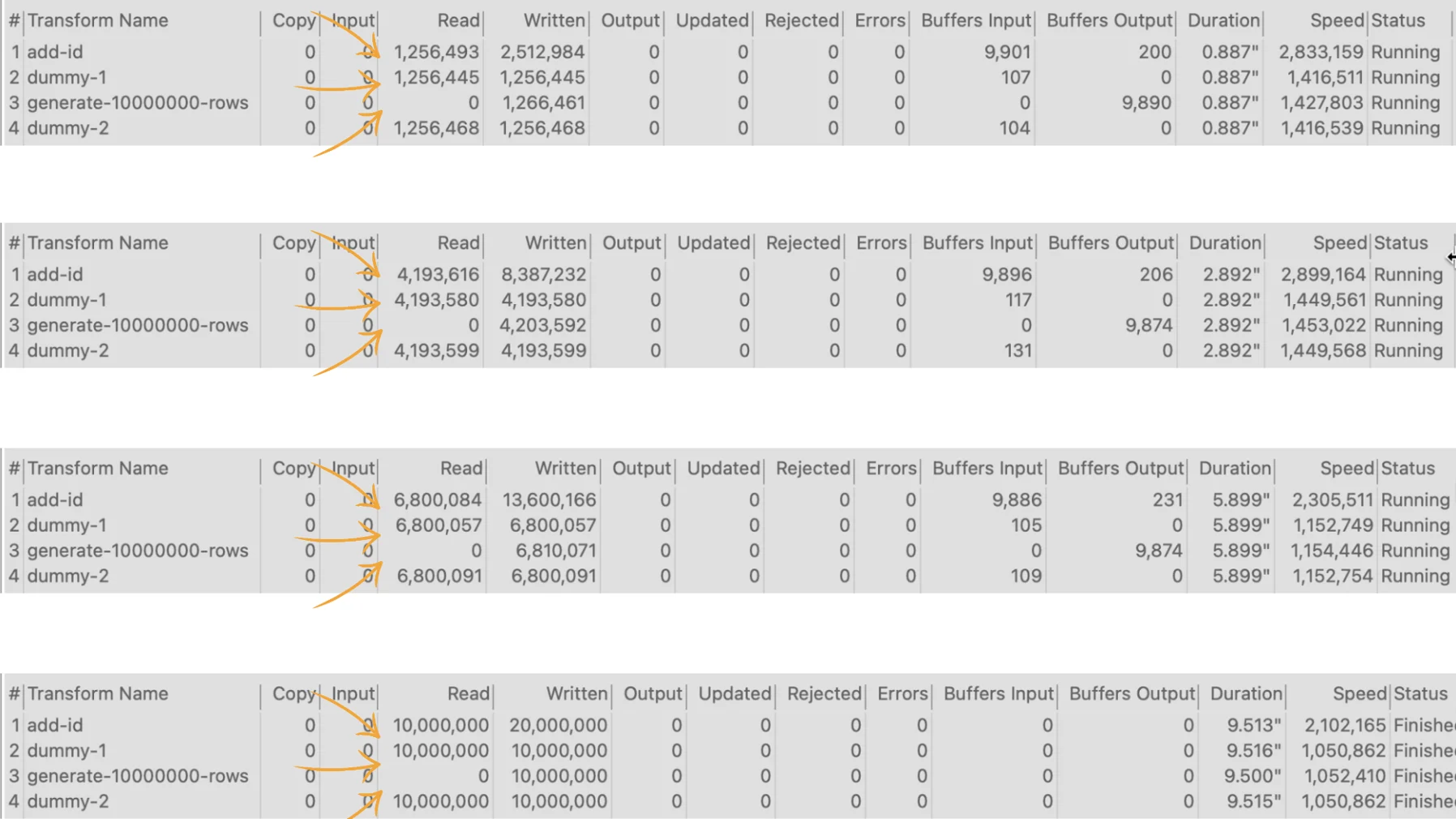
Note that the "Dummy" transforms progressively receive the rows after being processed by the "Add sequence" transform.
Also, note that both Dummy transforms receive the 10,000,000 rows. The Read metric for both is 10,000,000 at the end, while the Written metric for the "Add sequence" is 20,000,000 (the sum of both).

Remarks
#1 One of the most critical concepts in Apache Hop is that pipelines execute in parallel by default.
#2 By default, distribution governs data movement.
#3 Explicitly selecting the copy option ensures all connected transforms receive all rows.
By observing execution metrics and analyzing data movements, users can gain valuable insights into the performance of their pipelines and identify potential bottlenecks. For instance, scaling up the dataset to a larger volume can highlight how Apache Hop handles data processing at scale and provide valuable feedback for optimization.
Additionally, understanding data movements within a pipeline enables users to design more efficient workflows and improve overall productivity. By leveraging Apache Hop's parallel execution capabilities and selecting the appropriate data movement method, users can streamline their data processing tasks.
Don't miss the video below for a step-by-step walkthrough.
Stay connected
If you have any questions or run into issues, contact us and we’ll be happy to help.