
Hey everyone! This post explains how to choose between pipelines and workflows in data integration projects.
You'll learn through real-world examples when a workflow is more appropriate than a pipeline, especially when tasks must run in a specific order to avoid errors.

Pipelines or workflows?
When deciding between pipelines and workflows in your implementation, the basic approach boils down to this:
Pipelines:
- Use pipelines primarily for data transformation tasks.
- Pipelines are the backbone of data processing, responsible for reading, modifying, enriching, cleaning, and writing data.
- They serve as the workhorses of your data processing tasks.
- Pipelines can be orchestrated through other pipelines or workflows.

Workflows:
- On the other hand, workflows excel at orchestrating pipelines and workflows.
- They are sequences of operations that are typically executed sequentially, although they can support parallel execution if required.
- Workflows focus less on direct data manipulation and more on overarching orchestration tasks such as file execution, infrastructure verifications, email notifications, error handling, and more.

However, the decision between pipelines and workflows isn't always straightforward. It hinges on the specific requirements and varies depending on your scenario.
 Understanding the default execution behaviors—pipelines executing in parallel and workflows executing sequentially—is crucial in making the right choice.
Understanding the default execution behaviors—pipelines executing in parallel and workflows executing sequentially—is crucial in making the right choice.
Let’s explore a scenario that demonstrate when a workflow might be a more suitable approach than a pipeline.
Scenario
You have a pipeline designed to handle actors data stored in a PostgreSQL table.

The process involves extracting the year and filtering data for the current year, as each new actor added during this period requires individual file processing.
After filtering, each file is processed using a pipeline execution transform where the data is extracted and loaded into a new table. Following this, the processed data undergoes extraction again, and certain metadata is loaded into a separate metadata table.
In this pipeline, two distinct moments are crucial: first, the processing of data for the current year, and then the subsequent extraction after processing, utilized for metadata purposes.

Why is this pipeline incorrect?
This pipeline is unsuitable for its purpose because, to ensure proper processing, all current-year files must be loaded before extracting and loading metadata.
It fails to address the sequential nature of the tasks involved. Each transform starts concurrently, which can lead to issues when one task depends on the completion of another.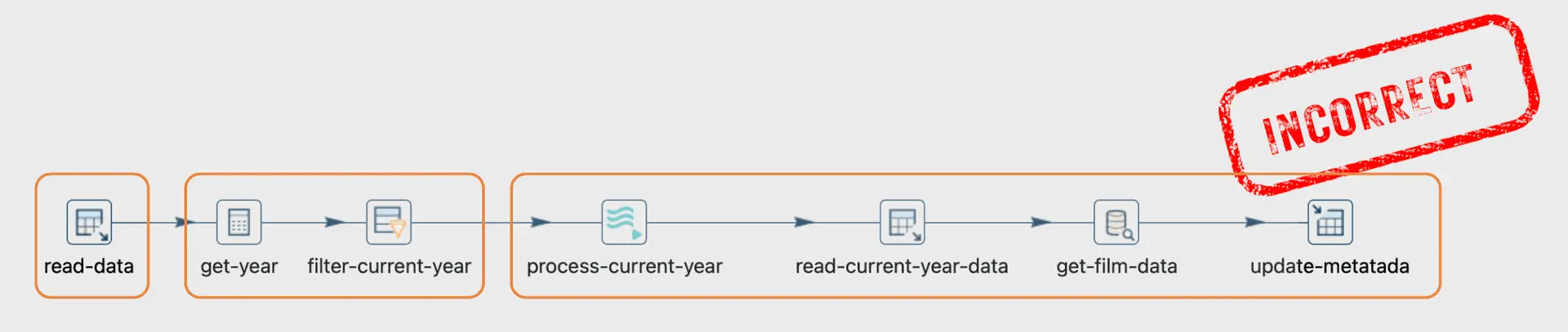
In scenarios where certain operations must be executed in a specific order, such as extracting data after it has been processed, this simultaneous execution approach is inadequate and can result in data inconsistencies or errors.
Given the simultaneous start of all transforms in this pipeline, it's imperative that the initial block executes first. Attempting to extract processed data before it's loaded would result in null output.
It's important to understand how pipelines execute and the execution metrics. Depending on the desired order of data transformations, you may need to choose between pipelines or workflows.
Fixing this
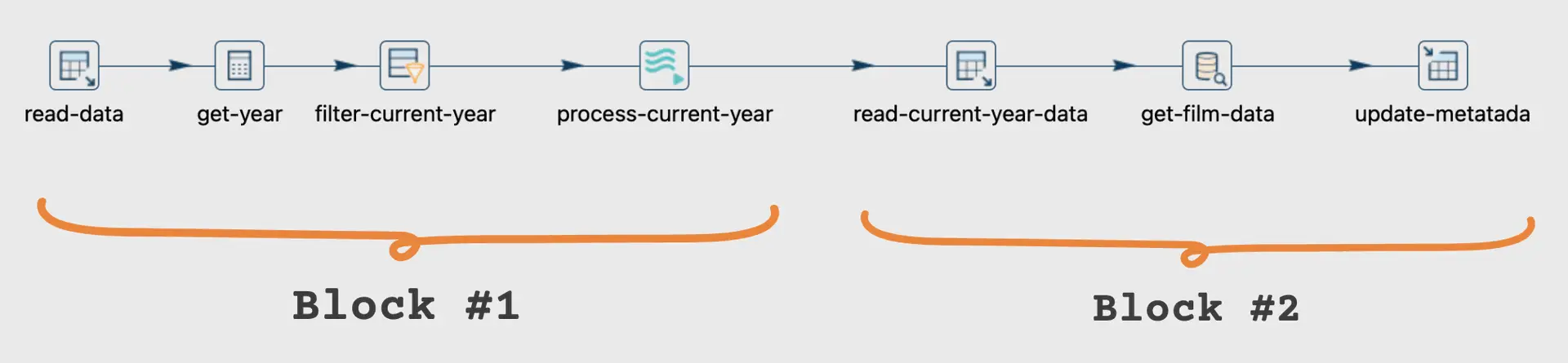
To address this issue, we need to ensure that the pipeline executes the tasks in the correct sequence. We can achieve this by restructuring the pipeline or employing a combination of pipelines and workflows.
Specifically, we should design the implementation to execute each block sequentially, ensuring that data processing and extraction occur in the required order.
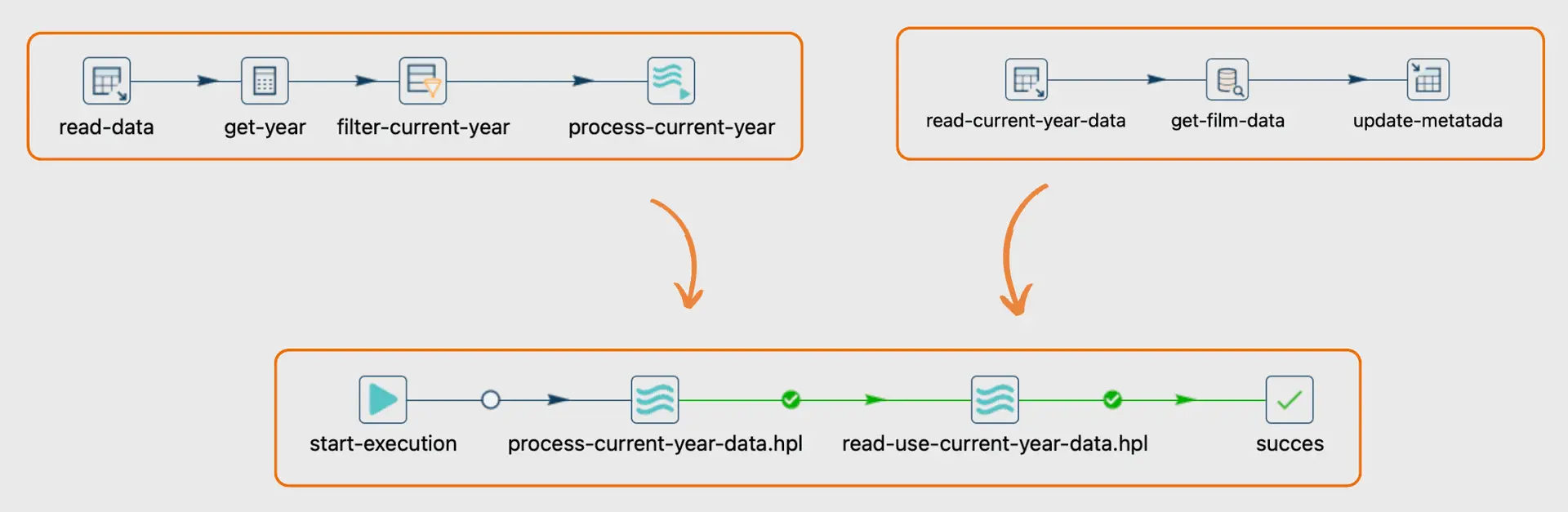
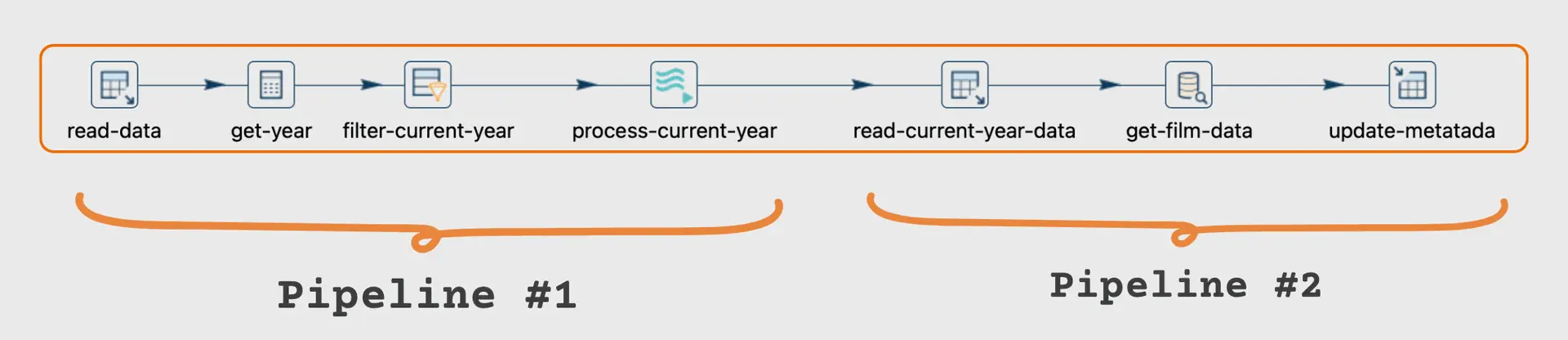
Pipeline #1:
The first pipeline handles extraction, filtering, and file processing.
Pipeline #2:
The second pipeline extracts the processed data and loads the metadata into a separate table.
Workflow:
Additionally, we can use a workflow to orchestrate the execution of multiple pipelines, allowing for more precise control over task sequencing and dependencies.
Remarks
- Pipelines run tasks in parallel, great for independent data transformations. However, if tasks depend on each other, this can cause errors—like trying to extract data before it's processed.
- Workflows run tasks sequentially by default, ensuring each step happens in the right order. This is key when handling dependent tasks, like in the scenario where processing data before extraction was crucial.
- Resolve issues by combining pipelines and workflows. Pipelines are suited for parallel tasks, while workflows ensure proper sequencing to prevent overlapping or incomplete data processing.
Conclusion
Choosing between pipelines and workflows is not always straightforward, but it’s essential to understand their roles in the context of your project’s requirements. Pipelines excel in parallel data processing, but when tasks need to run in a specific order, workflows offer better control and sequencing.
Don't miss the video below for a step-by-step walkthrough.
Stay connected
If you have any questions or run into issues, contact us and we’ll be happy to help.